
TrafficClaw: Agente LLM generalizable para control de tráfico urbano
Descubre TrafficClaw, un agente de IA basado en LLM que optimiza el control de tráfico urbano en entornos físicos unificados con aprendizaje por refuerzo.
Descubre TrafficClaw, un agente de IA basado en LLM que optimiza el control de tráfico urbano en entornos físicos unificados con aprendizaje por refuerzo.

Descubre MARFT, un nuevo marco de ajuste fino por refuerzo multi-agente para optimizar sistemas de agentes LLM. Mejora colaboración y razonamiento.

Descubre cómo RGPD, con redes gráficas y pesos dinámicos, mejora un 12% la precisión en RUL y SoH en motores, rodamientos y baterías.

Descubre cómo TuneAgent utiliza aprendizaje por refuerzo para ajustar el kernel de Linux, mejorando el rendimiento hasta un 5.6% de forma autónoma y precisa.

Los benchmarks actuales no revelan las fallas de los métodos de RL en LLMs. Descubre el OPG y principios para evaluar la generalización.

En TRMs, el razonamiento latente actúa como operador de mejora de política. Con RL y difusión, reducimos 18x los pasos.

Descubre el dilema entre representación y racionalización en RLHF: cómo el embedding afecta la consistencia de las recompensas y los límites de la optimización.

DeepLatent: revolucionario marco paralelo de razonamiento visual latente. Usa tokens 2D y RL continuo para alcanzar rendimiento de vanguardia en benchmarks clave.

Descubre cómo TS-OPSD recalienta políticas en RL sin profesor externo, restaurando entropía colapsada para mejorar el razonamiento de LLMs.
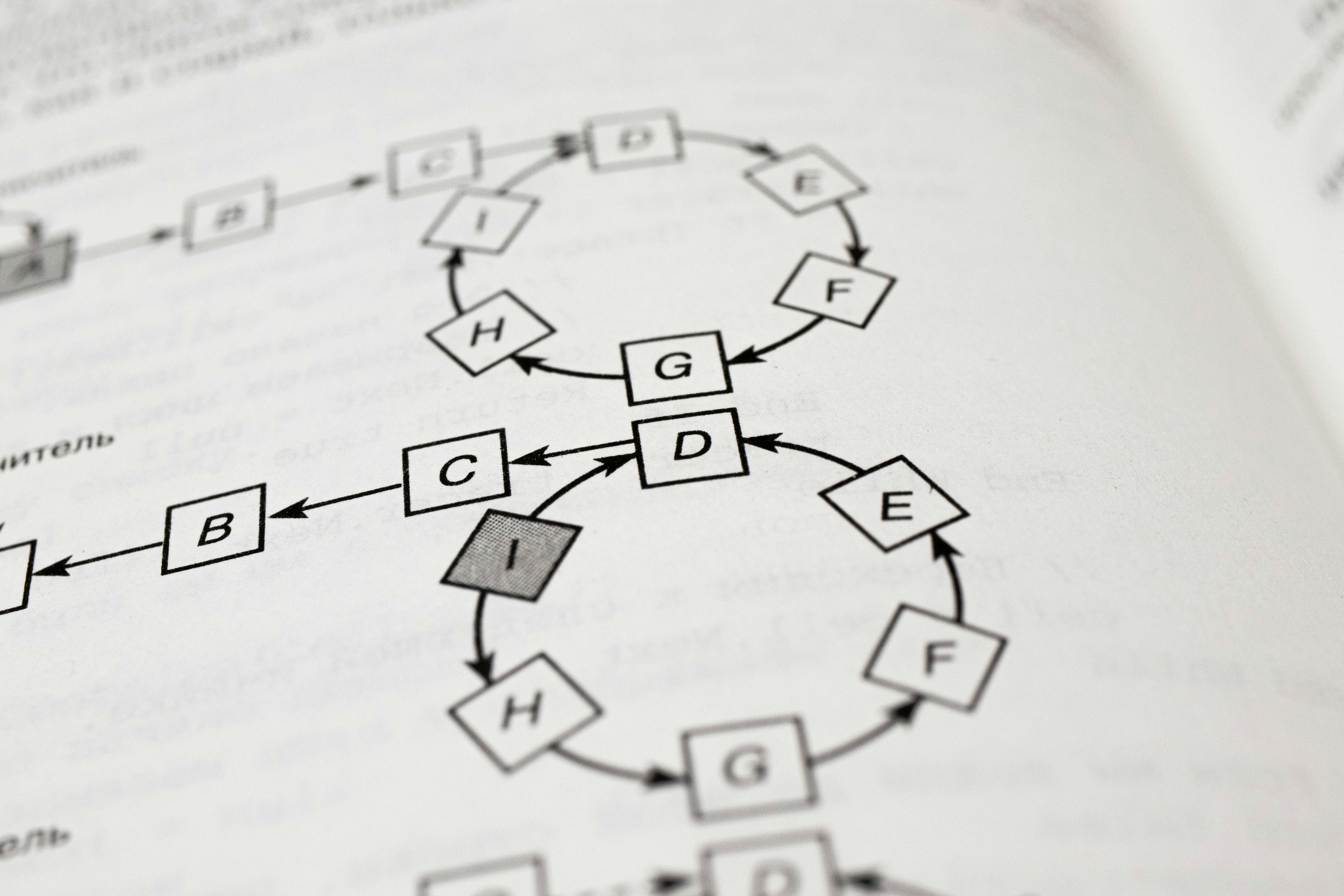
AdaE-SAEA: algoritmo evolutivo con ensambles adaptativos y RL para equilibrar robustez y precisión. Mejora rendimiento en problemas reales.

Descubre un algoritmo práctico y óptimo para bandits contextuales lineales con O(log log T) actualizaciones. Máximo rendimiento con mínima complejidad.

Nuevo método de aprendizaje por refuerzo reduce error de trayectoria en UAV de ala fija en un 86.77% respecto al autopiloto clásico. Descubre cómo el filtro HJB mejora la supervisión.

Descubre cómo ToMAP, un modelo de 3B parámetros, supera a GPT-4o en persuasión usando Teoría de la Mente. Aumenta efectividad un 39.4%.
El control neuronal Youla-REN garantiza estabilidad por diseño ante imprevistos. Ideal para entrenamiento con horizontes cortos y sistemas inciertos.

Nuevo marco OncoReason alinea LLMs con razonamiento clínico para predicción de supervivencia robusta e interpretable. Mejora F1 un 6% y reduce MAE un 12%.
Descubre cómo la relación señal-ruido no uniforme en el estimador REINFORCE causa inestabilidad y colapso durante el entrenamiento en RL.
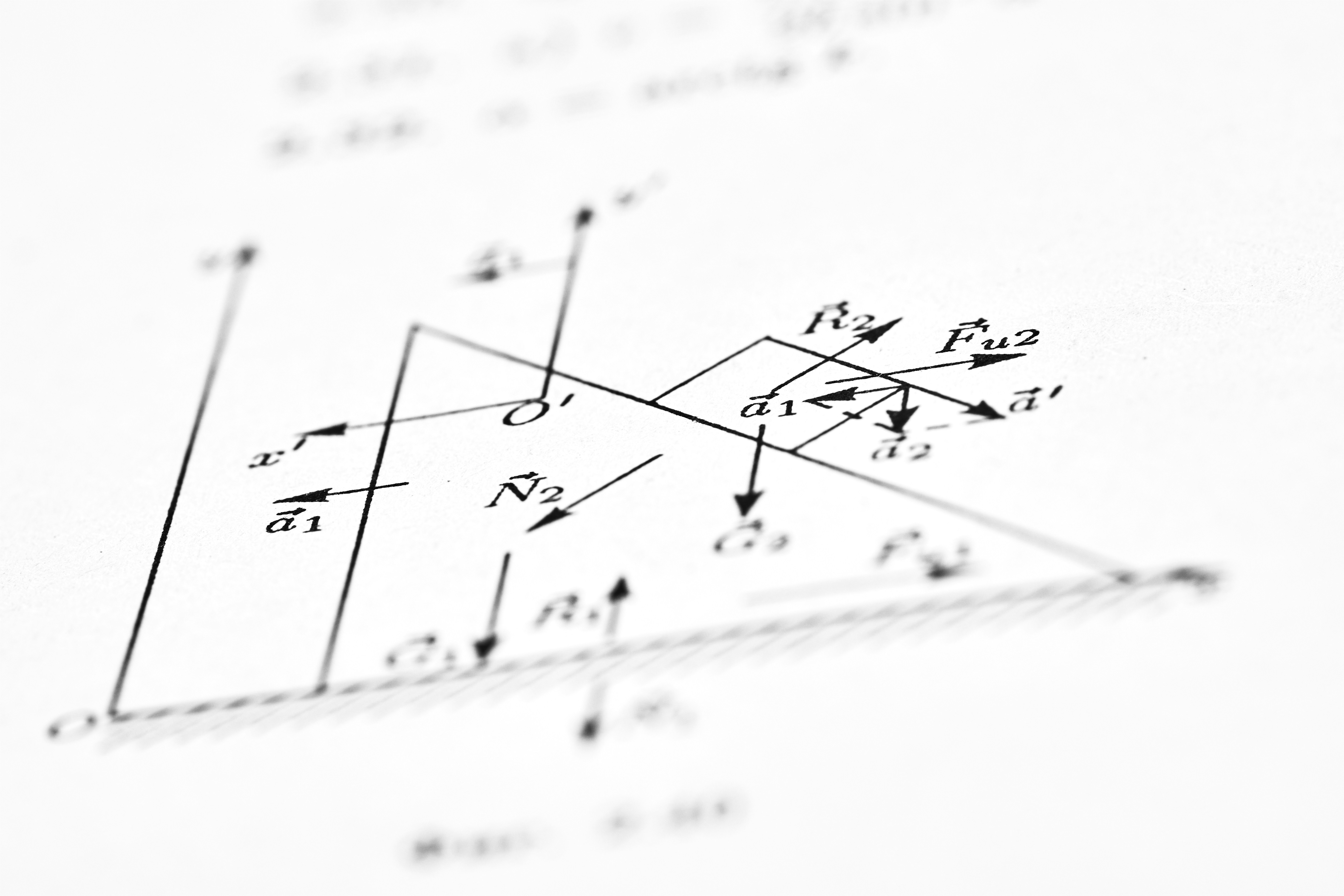
Nuevas divergencias Wasserstein y Kalman-Wasserstein mejoran el control KL, ofreciendo soluciones estables incluso con ruido bajo: doble integrador y cart-pole.

ForesightKV optimiza la evicción de caché KV en modelos de razonamiento, superando métodos previos con la mitad del presupuesto y aprendizaje combinado.

NestRL optimiza la colaboración humano-IA mediante entrenamiento anidado, logrando mayor adaptabilidad y rendimiento frente a métodos tradicionales en Overcooked.

Descubre MACCA, un nuevo marco de MARL offline que asigna crédito causal de forma precisa. Mejora el rendimiento en entornos sin interacción.